{kind=link}

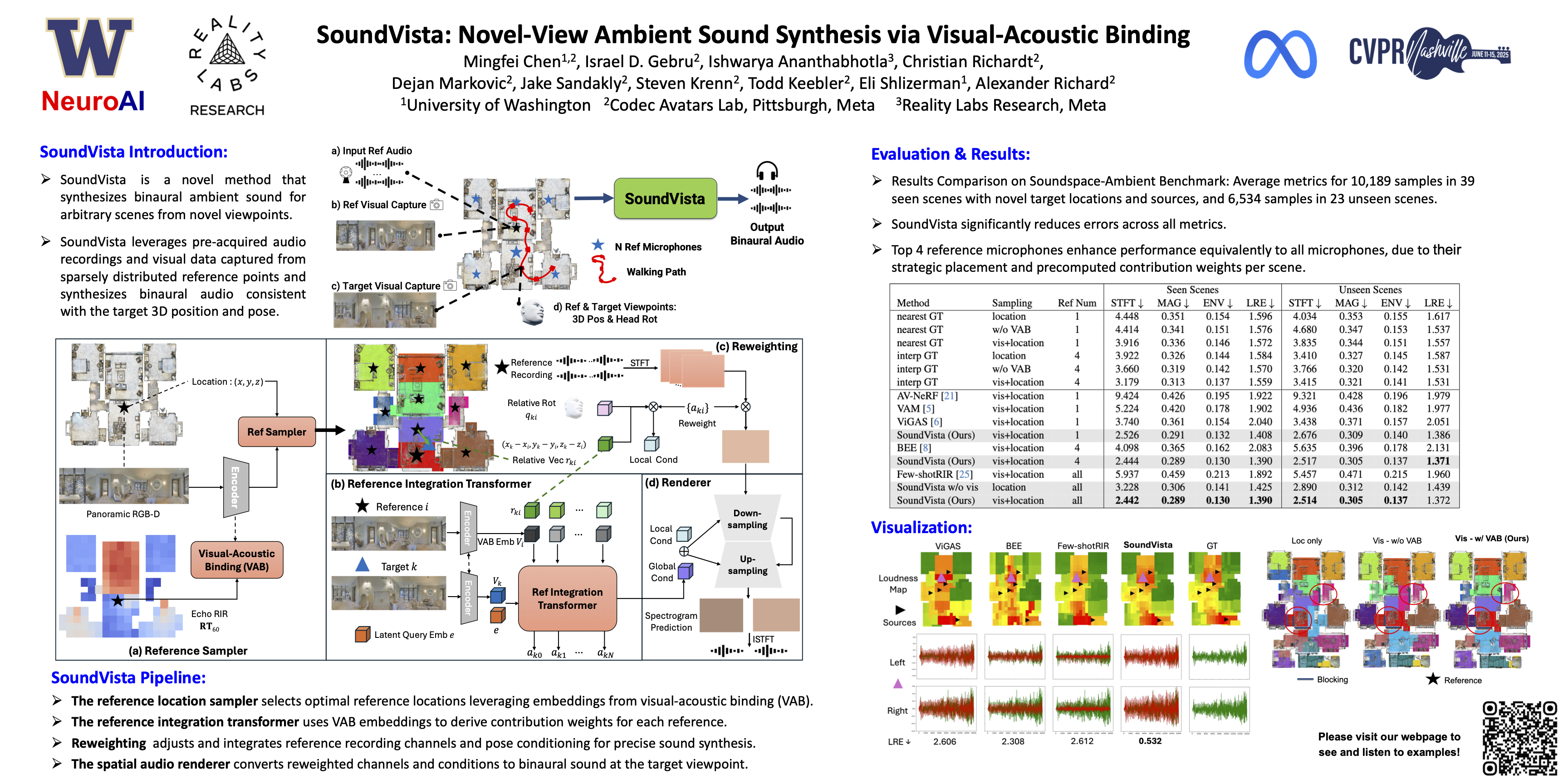
We introduce SoundVista, a method to generate the ambient sound of an arbitrary scene at novel viewpoints. Given a pre-acquired recording of the scene from sparsely distributed microphones, SoundVista can synthesize the sound of that scene from an unseen target viewpoint. The method learns the underlying acoustic transfer function that relates the signals acquired at the distributed microphones to the signal at the target viewpoint, using a limited number of known recordings. Unlike existing works, our method does not require constraints or prior knowledge of sound source details. Moreover, our method efficiently adapts to diverse room layouts, reference microphone configurations and unseen environments. To enable this, we introduce a visual-acoustic binding module that learns visual embeddings linked with local acoustic properties from panoramic RGB and depth data. We first leverage these embeddings to optimize the placement of reference microphones in any given scene. During synthesis, we leverage multiple embeddings extracted from reference locations to get adaptive weights for their contribution, conditioned on target viewpoint. We benchmark the task on both publicly available data and real-world settings. We demonstrate significant improvements over existing methods.
Please note: unmute the audio and listen with headphones for best experience.



@misc{chen2025soundvistanovelviewambientsound,
title={SoundVista: Novel-View Ambient Sound Synthesis via Visual-Acoustic Binding},
author={Mingfei Chen and Israel D. Gebru and Ishwarya Ananthabhotla and Christian Richardt and Dejan Markovic and Jake Sandakly and Steven Krenn and Todd Keebler and Eli Shlizerman and Alexander Richard},
year={2025},
eprint={2504.05576},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2504.05576},
}